Comparing the diversities of two communities
Before reading this, make sure you understand how to measure the diversity of a single community. Suppose you want to compare the epiphyte diversity of a primary forest to the epiphyte diversity of a disturbed forest. You take big samples of each of these two communities. Now you want to answer the question "Are the diversities different?" There are two parts to the answer. We must measure the magnitude of the difference, which enables us to judge its biological importance, and we must measure the statistical significance of the difference, to see whether it is arose by simple sampling variability or because of a real difference in diversity. These are completely different kinds of questions. Many published studies apply some statistical test and find statistically significant results, and then go no further. But mere statistical significance is not in itself interesting. Any tiny difference can be made statistically significant if sample size is large enough. Given that the difference is statistically significant, the more interesting question is: How big is the difference? Biologists have to get past their fixation on statistical significance and concern themselves more with this question of the size of the difference. The use of raw diversity indices made it difficult to answer that question in the past. If the Gini-Simpson indices of the communities are .99 and .97, is that an important difference or a small one? If the Shannon entropies (Shannon-Wiener indices) of the two communities are 4.5 and 4.1, is that a big difference or a little one? It is hard to say based on these numbers. At first glance the difference in Gini-Simpson indices of .99 and .97 looks small. But this index is highly nonlinear. Converting to effective number of species (which is the true diversity, as explained in the other parts of this site) proves that the difference is in fact huge: the community with a Gini-Simposn index of 0.99 has the same diversity as a community with 100 equally-common species, while the community with a Gini-Simposn index of 0.97 has the same diversity as a community with 33 equally-common species. The difference between a community with 33 equally common species and one with 100 equally common species is enormous. The same holds for the Shannon entropy values just mentioned: 4.5 converts to 90 effective species while 4.1 converts to 60 effective species. The second community is only 2/3 as diverse as the first community, according to this measure. If the diversity drops that much between undisturbed forest and disturbed forest, that is a serious and biologically significant drop. It is hard to realize that the drop is so dramaric if one looks only at the raw indices. Suppose you calculate the true diversities (effective numbers of species) and find a big drop. That is when it is time to ask the other question, the question of statistical significance: could such a drop be due to random sampling effects? If the samples are large, the t-test suggested by Hutcheson (1970) can answer this question for diversity of order 1 (Shannon measures). Randomization tests are also available. On this websit I do not deal with this side of the question because the statistical tests in the literature are mostly correct. Where the literature fails is in its treatment (or its lack of treatment) of the other (and more important) side of the question, the magnitude or biological significance of the difference. So, to compare the magnitudes of two diversities, calculate the effective numbers of species (the exponential of the Shannon entropy, for example) of the two communities so that you can compare them on a linear scale and get an intuitive feel for the difference. (Download my Excel sheet Indices to Diversities which does this conversion for you.)You can divide the smaller diversity by the larger one and come up with a meaningful fractional drop in diversity (something you can't do with raw diversity indices because they are nonlinear with increasing diversity). Then check to see if that drop could be due to chance, by calculating the t-test of Hutcheson (for Shannon measures) or other tests. If the difference in true diversities (effective numbers of species) is both large in magnitude and statistically significant, then you have found something important. Congratulations! Many researchers prefer to use presence/absence measures like species richness and its similarity-index relatives, Sorensen and Jaccard, even when frequency data is available. Often they do this because presence/absence measures are simple to interpret; many researchers have a lingering distrust of frequency-based diversity measures. The raw frequency-based indices were abused so much in the literature that this mistrust of the usual techniques was justified. However, conversion of these indices to effective number of species gives these measures many of the same intuitive properties that species richness has, and frequency-based measures will detect community differences more easily than presence-absence measures. Here are some examples from the literature that illustrate the above points:
Example 1, illustrating the increased power of frequency measures over presence-absence measures: An interdisciplinary team of scientists, including my friends Nigel Pitman and Mark Thurber, found an odd forest type on the western edge of Amazonia. Although the rest of western Amazonia is covered with the most diverse forests on earth, this one was peculiarly poor in species. The authors chose to express the diversities of each community using species richness, which is the diversity of order zero. They found that a plot in the odd forest had a species richness of 102 species while similar plots in the rest of the region had an average species richness of 239. Thus, according to species richness, the average forest plot is 2.3 times more diverse than the species-poor plot. That's quite a difference. However, species richness pays no attention to frequencies, and so it is not as good at detecting differences as a frequency-based measure would be. A virgin forest with fifty equally-common species is much more diverse than a burned forest with one abundant fire-tolerant invader species and a couple of individual survivors of 49 other species. Yet species richness is the same for both forests. It would be better to use measures sensitive to frequency, if frequency data existed. Nigel was kind enough to lend me his raw frequency data so I could figure out the Shannon or order-one diversities of the plots. Recall that the Shannon diversity is the fairest diversity measure, weighing each species exactly by its frequency, not favoring either rare or common species. (It is also the only diversity measure which can be decomposed into alpha and beta components when community weights are unequal.) The diversity of order one for the species-poor plot is 28.5 effective species while the average for the other upland forest plots is 134 effective species. In other words, the species-poor forest has the same Shannon entropy as a forest consisting of 28.5 equally-common species, and the normal forests have the same Shannon entropy as a forest with 134 equally-common species. The difference in diversity between the two forest types is therefore the same as the difference in diversity between a forest with 28.5 equally-common species and a forest with 134 equally-common species. That's a huge difference! Thus when frequencies are taken into account, the diversity of normal forests is actually almost 5 times higher than that of the poor forest. The difference is much greater than the 2.3 times indicated by species richness. [The original article containing this data is: Catastrophic natural origin of a species-poor tree community in the world's richest forest, by N. Pitman, C. Ceron, C Reyes, M. Thurber, J Arellano, published in Jour. Trop. Ecology, 2005, 21: 559-568. Download a pdf of this article by clicking on the title; article courtesy N. Pitman and M. Thurber.]
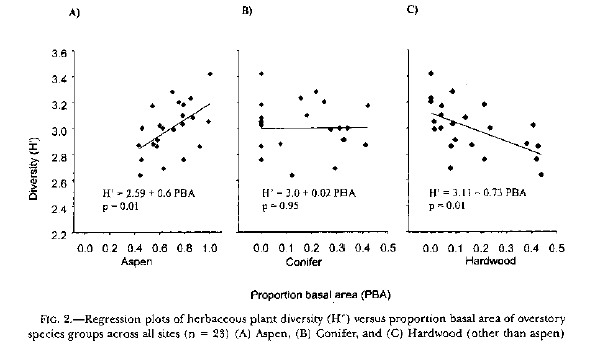
Example 2, a study that is typical of current research, which could be improved by calculating the real magnitudes of the effects being studied: In Overstory composition and stand structure influence herbaceous plant diversity in the mixed aspen forests of northern Minnesota, American Midland Naturalist 143: 111-125 (2000), Berger and Puettman measure the Shannon entropy of the herbaceous understory to see if it is correlated with overstory variables. The found the following correlations:
[Note that they incorrectly call H (or H') "diversity". H or H' is the entropy, not the diversity. We will see in the next example that this is not mere semantics but can have major practical consequences.] Concentrating on Graph A, which is the main point of their study, we see that Shannon entropy is significantly correlated with aspen basal area. But is the difference between 2.59 (the value of H' when aspen basal area is 0) and 3.19 (the value of H' when aspen basal area is 100% of total basal area) a big difference or a small one? The correlation coefficient and the p-value do not really answer this question, but this is all that Berger and Puettman report. Experienced biologists, who work often with Shannon H, will have an intuitive feel for the magnitude of the difference between 2.59 and 3.19, and will recognize it as a substantial difference. But what is the real magnitude of that difference? This is where conversion to effective number of species or true diversities is useful. The difference in herb diversity as one goes from 0 to 100% aspen basal area is the same as the difference between a forest with exp(2.59) = 13.3 equally-common herb species and a forest with exp(3.19) = 24.3 equally-common herb species. According to Shannon entropy, then, the herb diversity (the true diversity, not the index H) doubles as aspen basal area increases from 0 to 100%. This shows that Berger and Puettman have found an effect that is not only statistically significant but is actually quite large in absolute magnitude. It is unfortunate that there is no mention of the magnitude of the effect in their paper, it would have been a very useful addition to their conclusions. This is a common defect in the diversity literature, which tends to focus narrowly on statistical parameters and neglect the more important issue of the real magnitude of an effect. This neglect has been fostered by a lack of mathematically-appropriate measures of those magnitudes. Effective number of species, and the ratios, similarity measures, and overlap measures derived from it, are the appropriate measures.
Example 3, showing how ratios of raw diversity indices can mislead, and how this can be avoided by using effective numbers of species: In Species diversity in vertical, horizontal, and temporal dimensions of a fruit-feeding butterfly community in an Ecuadorian rainforest, Biological Journal of the Linnean Society 62:343-364 (1997), DeVries, Murray, and Lande explore the differences between tropical butterfly communities along many spatial and temporal dimensions. This is part of a series of pioneering papers on the subject, distinguished by their huge sample sizes and extensive temporal and spatial coverage. A measure of community similarity has been proposed by one of the authors (Lande 1996) and is used in this study to analyze similarity among communities along different ecological dimensions, like canopy vs. understory. The idea of the measure is as follows: Find the average diversity of the communities (the alpha diversity), and compare this with the total diversity of the pooled samples from all the communities (the gamma diversity). If the communities have few species in common, the total diversity of the pooled samples will be much greater than the average diversity of the individual communities. The ratio of alpha over gamma is his measure of similarity, a measure of shared diversity. It equals unity when all communities are identical in species composition. This would be an intuitive and well-behaved similarity measure if it used true diversities. But Lande (1996) uses raw indices instead of true diversities in his similarity measure. This is not a mere semantic issue, it causes real trouble. The Gini-Simpson index, which is Lande's recommended index of diversity, is always close to unity for diverse ecosystems. Thus both the alpha Gini-Simpson index and the gamma Gini-Simpson index will always be close to unity for diverse communites. Lande's similarity measure takes their ratio, which will therefore also be close to unity no matter how similar or different the communities are in species composition. This mathematical artifact, not biology, is responsible for the high similarity values published in this paper and elsewhere. The similarity between canopy and understory butterfly communities, using the Gini-Simpson index, is 0.975, indicating high similarity, even though (as the authors of the paper note) the communities are really quite distinct from each other. The similarity between habitats is also high, 0.935, and similarity between months is high as well, 0.978. Not only in this paper but in all published papers using this methodology, the Gini-Simpon similarity values are always high for diverse communities, between 0.93 and 0.99, regardless of what is being measured. The problem (and the solution) can be made clearer by idealizing the example somewhat. Suppose we have two equally-large communities with 500 equally common species in each. Their Gini-Simpson indices would each equal 0.998, and so the alpha Gini-Simpson index would also equal 0.998. Suppose the two communities were identical in species composition. Then the Gini-Simpson index of the pooled communities would also be 0.998, and Lande's index of similarity would be 0.998/0.998 = 1.000, correctly indicating complete similarity between the communities. Now let's assume instead that the two communities were completely dissimilar (i.e. they have no species in common). Then the pooled communities have a Gini-Simpson index of 0.999. Lande's similarity measure is therefore 0.998/0.999 = 0.999, indicating virtually complete similarity, even though the communities are in fact completely different! Obviously ecologists could easily reach wrong conclusions if they relied on this measure of similarity. This measure of "similarity" really does not measure similarity in any meaningful sense, because it is so strongly influenced by alpha diversity. The solution is simple: use true diversities (effective number of species) in Lande's similarity measure, not the raw indices. Regardless of the indices on which they are based, true diversities behave intuitively when made into ratios, because they have Hill's doubling property (discussed elsewhere on this site). In the example of the preceding paragraph, when the two communities are identical, the modified Lande's similarity measure would be (1/(1-0.998)) / (1/(1-0.998)) = 1.000, as it should. (Note that we first find the alpha Gini-Simpson index and then convert this to get the true alpha diversity; the alpha diversity is NOT the average of the effective numbers of species of the two communities. Lande showed in his 1996 paper that the latter is not a concave function and could give paradoxical results. My Ecology paper on the mathematics of alpha and beta diversity provides the theoretical justification of the definition of alpha diversity used here.) When the two communities are completely distinct, the modified Lande similarity is (1/(1-0.998)) / (1/(1-0.999)) = 0.50. This makes intuitive sense; if the two communities are completely different, the total pooled diversity is twice the diversity of any single community, so the average community contains half the total pooled diversity. If we had used Shannon entropy or some other diversity index instead of the Gini-Simpson index, we would still get 0.50 when the two communities are completely different. If there had been N distinct communities, we would get 1/N when the communities are completely distinct. Sometimes it is useful to have a similarity index that goes from 0 to 1 instead of 1/N to 1. When the similarity (really homogeneity) measure proposed here, using the Gini-Simpson effective number of species, is linearly transformed onto the interval [0,1], it turns out to be identical to the famous Morisita-Horn index of similarity. Effective number of species is a powerful conceptual tool which allows the derivation of many other interesting results as well. The Jaccard, Sorensen, and Horn indices, and the proper definitions of alpha and beta, all can be derived using this concept. This is the subject of my paper, Partitioning diversity into independnet alpha andf beta components, in Ecology Oct 2007.. More examples will follow when time permits. |